Scaling Development Teams with Ephemeral Environments – A Strategic Guide for CTOs
Explore how ephemeral environments help development teams scale efficiently. This strategic guide for CTOs covers key benefits, technical insights, and practical steps to boost deployment speed, reduce costs, and streamline testing.

Mélanie Dallé
April 11, 2025 · 7 min read
Mélanie Dallé
Mélanie Dallé, Senior Marketing Manager at Qovery, is a tech-savvy digital marketing expert.
See all articlesHiring more developers doesn’t guarantee faster shipping—especially when everyone’s stuck waiting in the same staging environment. Merge conflicts, test collisions, unpredictable bugs, and idle cloud resources turn simple deployments into days of delay.
For growing teams, traditional staging becomes a bottleneck. Ephemeral environments fix that by giving every pull request its own isolated, production-like environment—on demand.
In this article, we’ll look at why shared staging environments fail as teams scale, how ephemeral environments restore speed and safety, and what kind of impact they’ve had for teams like Talkspace and Julaya.
If your release process slows down as your team grows, this isn’t a tooling problem—it’s an environment problem. Let’s fix that.
#Why Traditional Staging Environments Fail
CTOs clinging to traditional staging environments face four critical pain points:
#Shared Environments Create Bottlenecks and Team Friction
A single shared staging environment becomes a chaos multiplier for growing teams. Merge conflicts erupt when changes from one feature inadvertently break another, forcing engineers to waste hours debugging environment-specific issues instead of actual code. Pipeline gridlock compounds the problem—a single failing test or delayed feature review can block the entire deployment queue, derailing sprint timelines (like Talkspace’s two-week delays caused by one blocking feature). Testing delays further slow momentum, as QA teams must wait for their "turn" to validate changes, leading to idle time and rushed cycles.
This "test environment traffic jam" forces engineers into a lose-lose choice: work outside staging (defeating its purpose) or endure unpredictable delays. Neither scales.
#False Positives and Production Escapes
Staging environments often mask bugs rather than reveal them. State pollution is a key culprit—lingering data from previous tests creates false positives, where a feature works in staging but fails in production due to mismatched datasets. Unrealistic interactions add risk: when multiple features are tested together, their combined behavior may not reflect how they’ll operate in isolation post-deployment, leading to integration surprises. Configuration drift worsens reliability over time, as manual tweaks and outdated dependencies cause staging to diverge from production.
#Skyrocketing Costs for Idle Resources
Traditional staging is always-on, burning cash for underutilized infrastructure. Overprovisioning is common—teams oversize staging environments (e.g., running extra database replicas) to prevent resource contention. Redundant environments multiply costs as teams spin up additional instances (like "staging-2" or "staging-qa"), each requiring separate maintenance and cloud spend. Orphaned resources—forgotten test deployments, abandoned branches, and idle CI/CD runners—silently inflate bills.
The financial drain is measurable: Julaya saved $15,000/year by replacing static staging with on-demand ephemeral environments.
#Operational Overhead and DevOps Bottlenecks
Manual environment management bogs down DevOps teams. Ticket queues pile up as developers submit requests for provisioning or debugging, forcing infrastructure teams to context-switch away from strategic work. Inconsistent setups emerge without IaC—each environment becomes a "snowflake," leading to "works on my staging" failures during deployment. Slow onboarding compounds delays, with new engineers waiting days for access or struggling to replicate staging locally.
The consequence? Deployment cycles stretch from hours to days, and innovation stalls as engineers wrestle with infra instead of code.
#The Tipping Point: When Staging Becomes the Bottleneck
For small teams, traditional staging may work—until it doesn’t. The breaking point typically arrives when:
- The engineering team grows beyond 10-15 developers.
- Microservices or distributed architectures multiply integration touchpoints.
- The business demands daily (or hourly) deployments.
At this stage, staging environments shift from safety nets to roadblocks. Teams that cling to them face:
- Deployment paralysis – Fear of breaking staging leads to fewer, riskier releases.
- Burnout – Developers and DevOps engineers waste cycles on environment management.
- Technical debt – Teams bypass staging entirely, deploying straight to production with inadequate testing.
These symptoms signal an unsustainable system. Ephemeral environments solve the core problem by decoupling testing from shared infrastructure, enabling teams to scale without the bottlenecks.
#The Technical Edge of Ephemeral Environments
Ephemeral environments address these pain points through four technical pillars:
#Pull Request-Based Environments (GitOps-Driven Architecture)
Every PR or feature branch spins up a fully isolated, production-like environment—complete with VPCs, databases, and microservices. Tools like Qovery automate this provisioning, unlocking three key advantages. First, parallel testing eliminates conflicts, letting developers validate changes independently. Second, QA accelerates as testers gain dedicated environments, removing pipeline friction. Third, merge cycles speed up—Talkspace achieved 20 consecutive on-time deployments after adopting this model, a 300% improvement over their shared staging workflow.
Below diagram illustrates the creation of a full-fledge ephemeral environment when a PR is created.
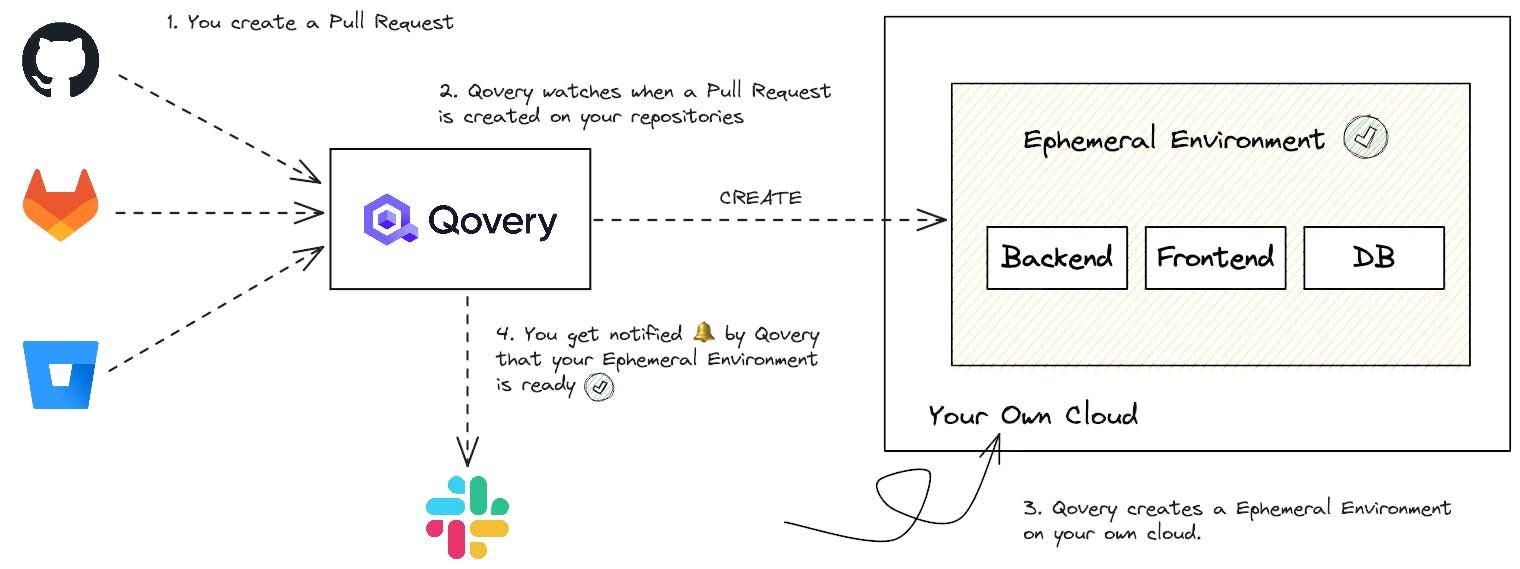
#Infrastructure-as-Code (IaC) Automation
Ephemeral environments make use of Terraform, Kubernetes, and Helm to codify infrastructure. This ensures reproducibility, eradicating "works on my machine" issues by mirroring production exactly. Compliance becomes consistent as security policies are enforced via code, not manual checks. Onboarding also speeds up—new engineers clone fully configured environments in minutes, bypassing days of setup.
#Dynamic Scaling (Spot Instances & Auto-Scaling)
Ephemeral environments leverage cloud elasticity to maximize efficiency. Non-critical workloads use spot instances to cut costs—Julaya significantly reduced infrastructure spend this way. Resources auto-terminate after PR merges or tests conclude, preventing idle waste.
#Improved Developer Experience (DevEx)
Self-service provisioning via CLI or API shifts power to developers. No more DevOps tickets—engineers gain autonomy to spin up environments on demand. The productivity payoff is stark: Ephemeral environments increased Julaya’s developer productivity by 35%, cutting delivery time and streamlining lifecycle ownership.
#Why Ephemeral Environments Are Game-Changing for Scale
Beyond fixing staging bottlenecks, ephemeral environments unlock strategic advantages:
#Microservices Testing at Scale
Modern architectures demand testing distributed systems without the chaos of shared staging. Ephemeral environments deliver true isolation—microservices are tested with mocked or real dependencies in production-like settings, eliminating false positives from overlapping changes. Event-driven validation (e.g., Kafka queues or Webhooks) simulates real-world flows, critical for fintech or IoT platforms. Parallel pipelines let teams test 50+ microservices concurrently—imagine a ride-hailing app validating surge pricing logic independently from driver dispatch.
#Accelerating Mergers & Acquisitions
M&A integration simplifies with codified environments. Acquired teams onboard in days, not months, using IaC to mirror the parent company’s tech stack. Legacy systems can be cloned safely—a bank merging with a crypto startup, for example, can test ledger integrations in isolation before migration.
#Edge Computing & Geo-Specific Testing
Global apps require region-aware testing. Ephemeral environments spin up geo-specific clones—validating GDPR compliance in EU-only setups or CDN rules in Sydney vs. Virginia. IoT/5G teams replicate edge conditions (e.g., low-bandwidth farm sensors) without physical hardware.
#Security & Compliance Without Drag
Zero-day patching happens safely in isolated clones before rolling fixes to production. Audit trails auto-generate per test run—HIPAA workloads, for instance, gain disposable artifacts for compliance proofs.
#Cost-Efficient Experimentation
Blue/green deployments scale effortlessly—test Postgres 16 migrations across hundreds of ephemeral instances without staging gridlock. AI/ML teams train models in parallel environments (a computer vision startup cut experiment time by 60% by avoiding GPU contention).
#The Key Metrics That Matter to CTOs
Ephemeral environments directly impact seven KPIs critical for scaling teams:
#Deployment Frequency
High-performing teams deploy code multiple times per day. Ephemeral environments eliminate merge conflicts and staging queues, enabling uninterrupted deployment pipelines.
Elite DevOps teams deploy on-demand (multiple times daily), while low performers deploy once per month.
#Lead Time for Changes
The time from commit to production is a critical measure of agility. Ephemeral environments slash delays by enabling parallel testing and instant provisioning.
Top-tier teams have a lead time of under one hour for small changes, versus one week+ for laggards.
Julaya reduced lead time from 48 hours to 2 hours by replacing manual staging setups with automated ephemeral environments.
#Mean Time to Recovery (MTTR)
When failures occur, ephemeral environments accelerate debugging by providing exact replicas of the issue’s context.
Teams with fully automated recovery workflows resolve incidents much faster than those relying on manual processes. E.g. A fintech client replicated a payment gateway failure in minutes using a versioned ephemeral environment, cutting MTTR from 4 hours to 12 minutes.
#Cost per Deployment
Traditional staging wastes resources on idle infrastructure. Ephemeral environments leverage auto-scaling and spot instances to align costs with actual usage.
Dynamic environments can reduce cloud costs by 25–40% by eliminating over-provisioning.
#Developer Productivity
Reducing friction in the development lifecycle directly impacts output. Ephemeral environments eliminate wait times for environment provisioning.
Engineers lose previous hours per month to toolchain inefficiencies
#Infrastructure Utilization
Ephemeral environments ensure resources are active only when needed, optimizing cloud spend.
Typical staging environments run at <30% utilization, while ephemeral environments peak at 85%+ during active testing.
A SaaS company reduced idle Kubernetes cluster costs by 60% by auto-terminating ephemeral environments post-testing.
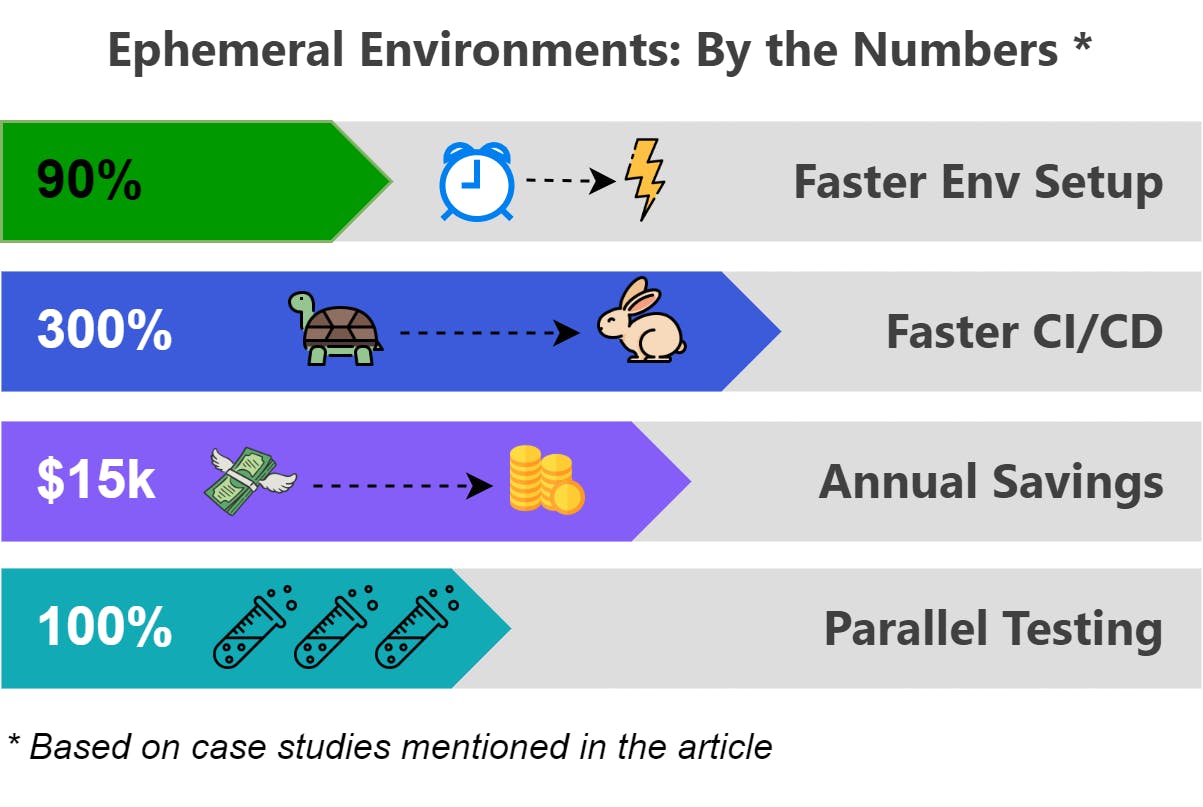
#Conclusion
Staging environments often start as a good idea - but they rarely scale. As teams grow, what was once a safety net becomes a bottleneck: delayed releases, frustrated developers, and wasted infrastructure.
Ephemeral environments fix this by making testing faster, isolated, and closer to production. No more waiting for a shared slot. No more “it worked in staging.” Just clean, disposable, on-demand environments for every pull request.
Teams like Talkspace and Julaya didn’t just improve deployment speed - they reduced costs, boosted developer autonomy, and simplified release workflows.
If your team is struggling to ship fast without breaking things, ephemeral environments aren’t a luxury, they’re an operational upgrade.
Give your team the right tools, and they’ll move faster, with more confidence. Try Qovery or request a demo to see how ephemeral environments can transform your development team.
Your Favorite DevOps Automation Platform
Qovery is a DevOps Automation Platform Helping 200+ Organizations To Ship Faster and Eliminate DevOps Hiring Needs
Try it out now!
Your Favorite DevOps Automation Platform
Qovery is a DevOps Automation Platform Helping 200+ Organizations To Ship Faster and Eliminate DevOps Hiring Needs
Try it out now!

