The Cost of Upgrading Hundreds of Kubernetes Clusters
At Qovery, we manage hundreds of Kubernetes clusters for our customers on different Cloud Providers. For most non-operational people, it’s hard to understand what it means behind the scene, the amount of work it represents, pitfalls we can encounter, and associated complexity.
Our customers are coming for several reasons, but they’re all happy to have Qovery management on the Kubernetes maintenance and upgrade stack.
On our side, it’s too many clusters to manage them manually. Automation is key! We developed our tooling around it to make automation, observability, and alerting possible.

Pierre Mavro
June 28, 2023 · 7 min read
Pierre Mavro
Pierre is an SRE and CTO of Qovery. He has 15+ years of experience in R&D, from the financial to the Ad-Tech industry; he has a strong knowledge of distributed and highly-reliable systems. He's also the MariaDB High-Performance book author.
See all articles#Kubernetes lifecycle
Qovery runs on managed Kubernetes offers provided by cloud service providers; nowadays, we already have the chance to have a simplified way to upgrade Kubernetes. For example, AWS EKS has an automated way to upgrade Kubernetes from one minor version to the next.
It first upgrades master nodes, then proceed to worker nodes.
ℹ️ Reminder:
- Master nodes: where the Kubernetes API servers are running, the controllers, schedulers, etcd (distributed storage)…by design, highly available
- Worker nodes: where the user workload runs, so we added several Qovery built-in logic to make it highly available and product side configuration to let customers tune this part (Health checks)
Master nodes are generally not an issue and are well-managed by the cloud provider. However, Worker nodes upgrades can easily fail for several reasons:
- Deployed Kubernetes objects are not compatible anymore with the next Kubernetes version
- Deployed applications use deprecated Kubernetes API versions objects and require to be updated (ex: CRDs, vXalphaX/vXbetaX/vX…)
- Some elements can be poorly configured or in bad shape, blocking the upgrade (ex: Pod Disruption Budget, wrong label selectors, pull image failure because the image does not exist anymore… leading to upgrade failures)
- Testing all elements together to ensure reliability between upgrades is complex, takes a long time, and costs money. Moreover, if you want to replicate your infra to validate before upgrading. Reminder: Kubernetes release cycle: one new version every three months!!! The end of life by the Kubernetes community is only one year!
- Not enough quotas Cloud provider side, so new nodes with newer versions can’t spin up.
If you don’t spend time on the upgrade part, Cloud providers will force the upgrade for you. You may come in unresponsive services at some points because of API incompatibility.
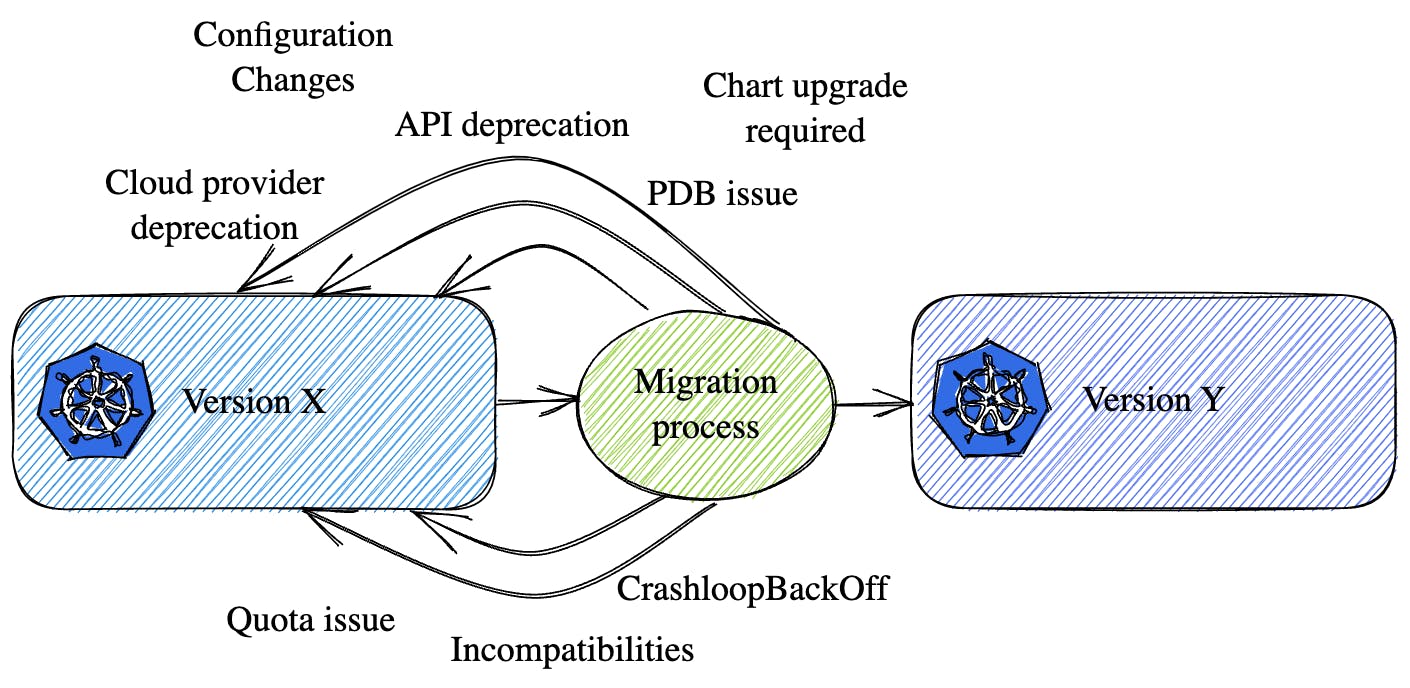
Finally, something that looks straightforward at first sight is more complex than expected.
Everybody wants the power of Kubernetes, but it has a cost! As you understand, managing a Kubernetes cluster is not that simple. Managing hundreds, and soon thousands, can’t be done if not automated. This is why we invested time in automation, and we’ll see how we did it in this article!
#Kubernetes Pre-Upgrade
#Changelog
Before upgrading, we look at Kubernetes Changelog on the community site and the Cloud provider changelog.
Once done, we update in the Qovery Engine everything related. Wait…I didn’t talk about it! The Qovery Engine is all the logic about cluster and app deployments. It’s free, Open Source, written in Rust. You can find the code here.
#API deprecation
We then use tools to check what’s deprecated for the future version. Several exists today. You can find the following:
We then update charts made by Qovery if there are updates required.
4:26PM INF >>> Kube No Trouble `kubent` <<<
4:26PM INF version 0.7.0 (git sha d1bb4e5fd6550b533b2013671aa8419d923ee042)
4:26PM INF Initializing collectors and retrieving data
4:26PM INF Target K8s version is 1.23.16-eks
4:26PM INF Retrieved 74 resources from collector name=Cluster
4:26PM INF Retrieved 224 resources from collector name="Helm v3"
...
4:26PM INF Loaded ruleset name=deprecated-1-26.rego
4:26PM INF Loaded ruleset name=deprecated-future.rego
__________________________________________________________________________________________
>>> Deprecated APIs removed in 1.25 <<<
------------------------------------------------------------------------------------------
KIND NAMESPACE NAME API_VERSION REPLACE_WITH (SINCE)
PodSecurityPolicy <undefined> grafana policy/v1beta1 <removed> (1.21.0)
PodSecurityPolicy <undefined> aws-node-term-handler policy/v1beta1 <removed> (1.21.0)
PodSecurityPolicy <undefined> loki policy/v1beta1 <removed> (1.21.0)
PodSecurityPolicy <undefined> eks.privileged policy/v1beta1 <removed> (1.21.0)
__________________________________________________________________________________________
>>> Deprecated APIs removed in 1.26 <<<
------------------------------------------------------------------------------------------
KIND NAMESPACE NAME API_VERSION REPLACE_WITH (SINCE)
HorizontalPodAutoscaler nginx-ingress nginx-ingress-ingress-nginx-controller autoscaling/v2beta2 autoscaling/v2 (1.23.0)For example, we can see deprecation.
#Infrastructure charts bump
Finally, we update all infrastructure charts deployed by Qovery. To maintain charts with their respective versions, we’re using Helm freeze. We've built an internal tool (Open source as well), allowing us to bump charts in a specific version and manage them in a GitOps way. Here is a small example:
charts:
- name: grafana
version: 6.16.10
repo_name: grafana
repos:
- name: stable
url: https://charts.helm.sh/stable
- name: grafana
url: https://grafana.github.io/helm-charts
destinations:
- name: default
path: chartsAll those charts are stored in the Qovery Engine Git repository, making it easy to make a diff between versions and to test.
#Infrastructure charts upgrades
Updating charts can look easy with "git diff". Honestly, it’s so easy to fail on updates made because we’re all human; it’s a manual job. Sometimes, default Chart values in the "values.yaml" file change. But if you don’t look at what has changed profoundly in the Charts you’re using, you can also have nasty surprises (services names or labels changed, reworked a Statefulset leading to data loss because of PVC name changes etc…).
This is why we instrumented our Engine to support several checks and keep essential things under control. We regularly add new checks to count on them at maximum on tests. Here are a few examples you can easily find on our Engine repository.
Bitnami MySQL chart: at Qovery, we use Bitnami charts for our database because the quality of their work is pretty good. However, they are not good at keeping compatibility and breaking changes over the years. Extra efforts have to be made on our side to find those breaking changes, for example:
# -master is required to keep compatibility with previous installed versions nameOverride: "{{ sanitized_name }}-master" fullnameOverride: "{{ sanitized_name }}-master"Did it remind you when GitHub decided to move from the default Master branch to the Main? 😅
#Advanced charts validation
Manual changes are not a solution. We added several instrumentations in our Engine to automatically help us with upgrades.
The first is a YAML check for "values.yaml" overrides. It’s easy to miss something important in a chart update; we’ve added an automatic control to values we override. They should be declared in the YAML and the code. Otherwise, it fails and denies the deployment, so we created a unit test for it:
/// Make sure rust code doesn't set a value not declared inside values file.
/// All values should be declared / set in values file unless it needs to be injected via rust code.
#[test]
fn cluster_autoscaler_chart_rust_overridden_values_exists_in_values_yaml_test() {
// setup:
let chart = ClusterAutoscalerChart::new(
None,
"whatever".to_string(),
"whatever".to_string(),
"whatever".to_string(),
"whatever".to_string(),
HelmChartNamespaces::Prometheus,
true,
);
let common_chart = chart.to_common_helm_chart();
// execute:
let missing_fields = get_helm_values_set_in_code_but_absent_in_values_file(
common_chart,
format!(
"/lib/{}/bootstrap/chart_values/{}.yaml",
get_helm_path_kubernetes_provider_sub_folder_name(
chart.chart_values_path.helm_path(),
HelmChartType::CloudProviderSpecific(KubernetesKind::Eks)
),
ClusterAutoscalerChart::chart_name()
),
);
// verify:
assert!(missing_fields.is_none(), "Some fields are missing in values file, add those (make sure they still exist in chart values), fields: {}", missing_fields.unwrap_or_default().join(","));
}#Chart breaking changes
Upgrading charts is sometimes simple, but sometimes it requires reinstalling a chart because of immutable values. Hopefully, it’s rare for the very sensitive workload that breaking changes occur. However, for several other applications which can’t be upgraded, we added a way to simplify the reinstall process:
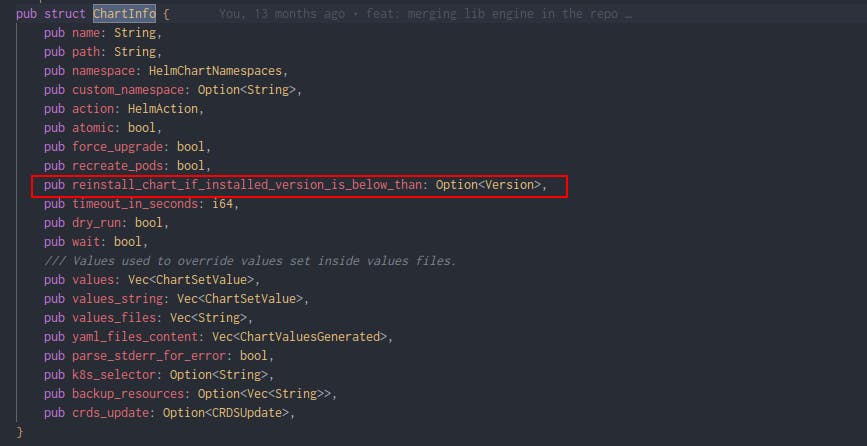
As you can see, other useful features (CRD updates, backups). Qovery Engine instrumentation and automation for Kubernetes Charts is key!
#Kubernetes upgrade
#Validation and preparation
When everything is validated, we move our own test cluster to this new version for internal validation for some weeks.
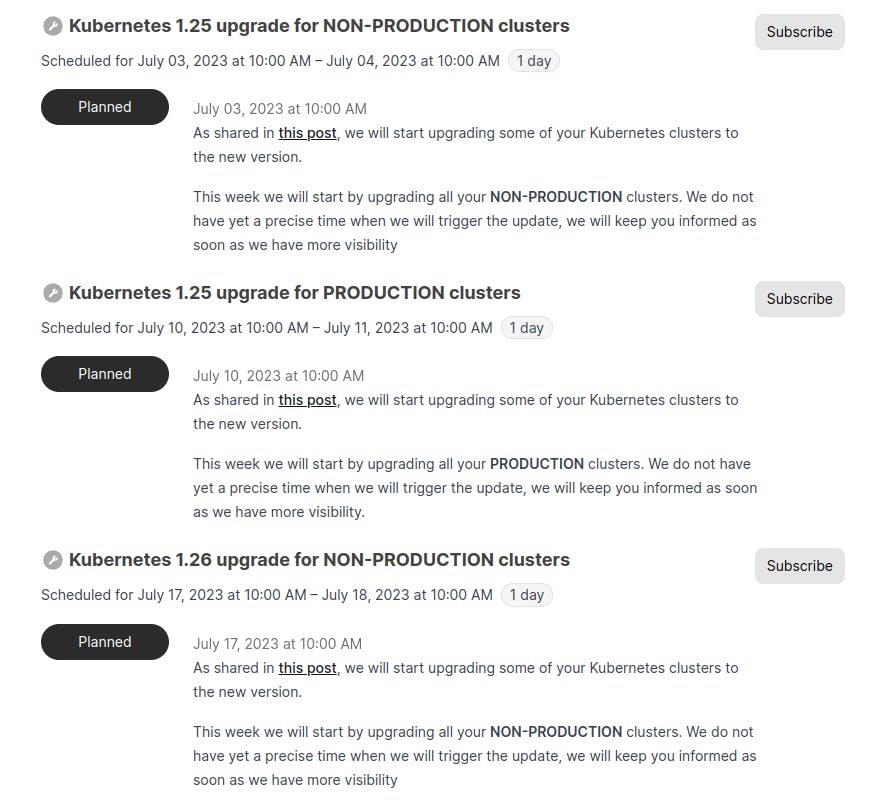
Once we’re ready, then we will announce the upgrade dates on our status page and the forum:
- Forum: https://discuss.qovery.com/t/important-kubernetes-upgrade-moving-to-1-24-1-25-1-26/1916
- Status page
#Upgrade customers non-production clusters
We first rollout a small batch of non-production clusters and keep an eye on it:
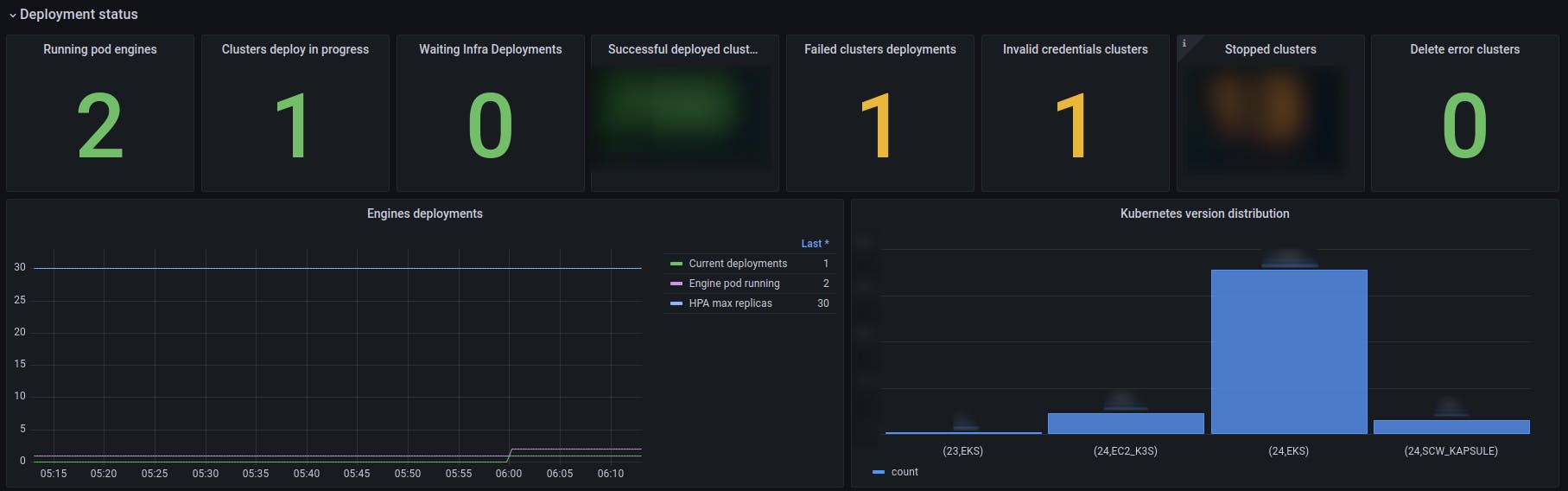
It allows us to fix undesired issues before rolling out the remaining clusters.
ℹ️ Cluster upgrades vary depending on the cluster size. Small clusters upgrade (<20 nodes) can take half an hour, while bigger clusters (<500 nodes) can take several hours.
#Upgrade customers production clusters
Finally, after some time (a week or two), customers could check everything was running smoothly on their side so that we can upgrade Production clusters as well.
#What’s next?
#More tests
We have several kinds of tests to validate the chart updates. We also have unit tests, functional tests, and end-to-end tests.
We spent months…years getting the correct level of deployments with the options we wanted.
Did we finish? No! The amount of work to get everything 100% covered is….huge! But we have enough tests to make us confident today for production usage!
#OpenSource and community
We’ll continue investing in the Qovery Engine and consider decoupling some parts into multiple open-source libraries to spread this work with the community 🙂.
#Upgrade schedule
Kubernetes upgrade is recurrent and frequent. We want to give more control to our customers and plan to let them plan when they want to have their production upgrades occur, so stay tuned ;)
Your Favorite Internal Developer Platform
Qovery is an Internal Developer Platform Helping 50.000+ Developers and Platform Engineers To Ship Faster.
Try it out now!
Your Favorite Internal Developer Platform
Qovery is an Internal Developer Platform Helping 50.000+ Developers and Platform Engineers To Ship Faster.
Try it out now!
