
MCP Server is the future of your team's incident’s response



Every engineering leader knows the cost of the 2 AM page. It’s not just the downtime; it’s the cognitive load placed on a sleep-deprived engineer trying to navigate a fragmented microservices architecture. In modern environments, a simple "certificate expired" alert involves a labyrinth of Kubernetes objects, Cloudflare DNS records, and challenges.
When your systems are complex, your runbooks become static fossils. They are hard to maintain, slow to search, and often irrelevant by the time an incident occurs.
The Shift: Documentation as Code, Investigation as Prompt
At Qovery, one of the recurrent incident topics has been Certificate issuance. Our certificates are created thanks to the amazing service of Let's Encrypt using DNS-01 challenge, to be able to request wildcard domain in the SAN. Our DNS are managed by Cloudflare which are automatically updated with an external-dns running on kubernetes, and the whole flow for the issuance is piloted by cert-manager.
That's a lot of moving parts needed to get a certificate, and it is never clear, especially for newcomers and even less during an incident, what is responsible for what.
Ha I know, It's external-dns that's in charge of managing DNS for the cluster ! 15 min later, and wait no, in the case of Certificate with DNS-01 challenge, it is cert-manager that create the TXT records via the ClusterIssuer !
To get the full picture of what is happening, one must investigate and consolidate all the status,log and configuration scattered from all those objects.
DNS-01 challenge -> ClusterIssuer -> cert-manager creates TXT records -> Certificate -> Certificate-Request -> Order -> Challenge
HTTP-01 challenge -> dns records must exist -> cert-manager creates pod + ingress to answer Let's encrypt http call -> Certificate-Request -> Order -> Challenge
Even if you are lucky, and you are coding your own probes to monitor it all, no alerting strategy can focus on all those elements. The operator still needs to understand the full chain to investigate and resolve the issue. The best approach is to set a high level alerts on the certificate with a ceiling number of days before expiration, and to document the investigation process in your team’s runbook.
Enter MCP: Turning Runbooks into "Hero" Journeys
This is where the MCP server changes the game. Runbook like all documentations are static assets, you need to maintain it up to date and for it to be effective it must cover all the scenarios. MCP server on the other hand is code and the LLM adapts to the real-time data it retrieves. It is a bit like reading a book where you are the hero.
MCP servers allows you to encode 2 main things:
- GuidedScenarios: hardcoded prompts that tell the LLM which role he should take and which data it should pay attention too
- Real-time Data Retrieval: Custom tools that allow the LLM to safely "touch" production (read-only) to see exactly what is happening now.
The Proof: From 30 Minutes to 30 Seconds
I built a reference MCP server in Rust specifically tailored to investigate certificate issuance issues. The code is available here
To play with it, clone the repository and run the commands
```
cargo build
claude mcp add incident-response -- target/debug/mcp_server_example
```
The MCP server allows the operator to use 5 tools in read-only mode, meaning that the call is not going to mutate any state on the production, only retrieving some data.
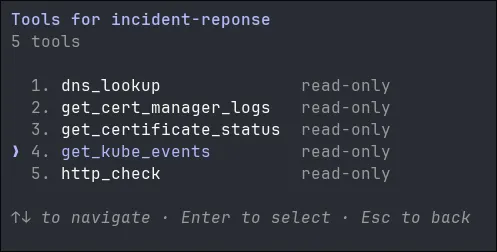
The server also provides a single scenario/prompt that allows the operator to investigate certificate issues with the mentioned above tools.

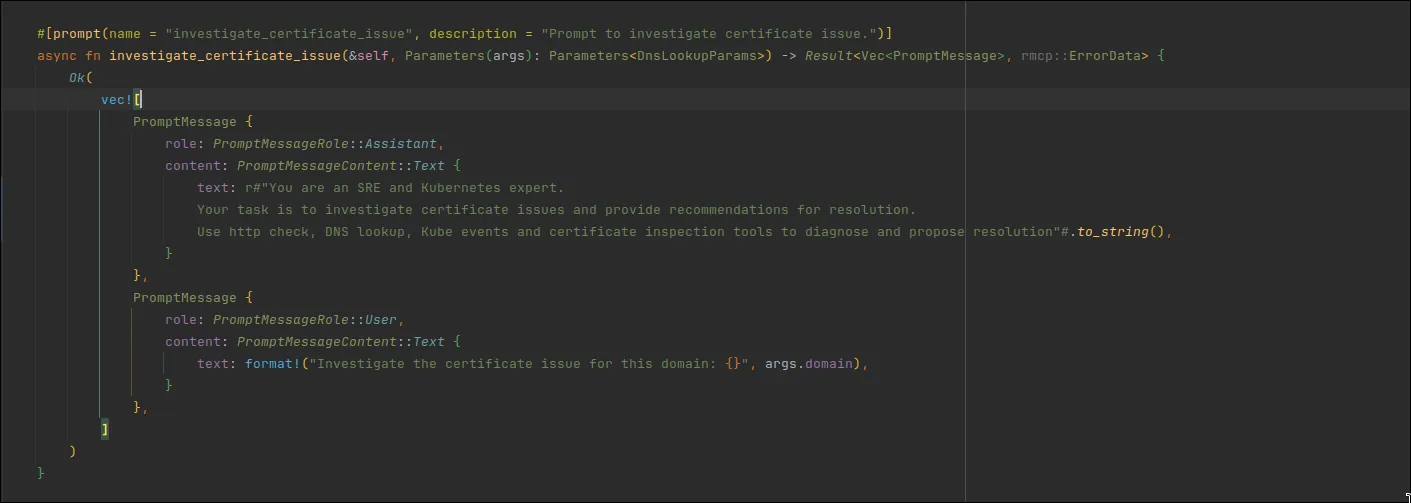
The prompt receive a single parameter, which is the domain to investigate, and will use all the tools at its disposal to track and locate the issue.
Even with such a rudimentary prompt and only 5 tools available, the result is quite powerful.
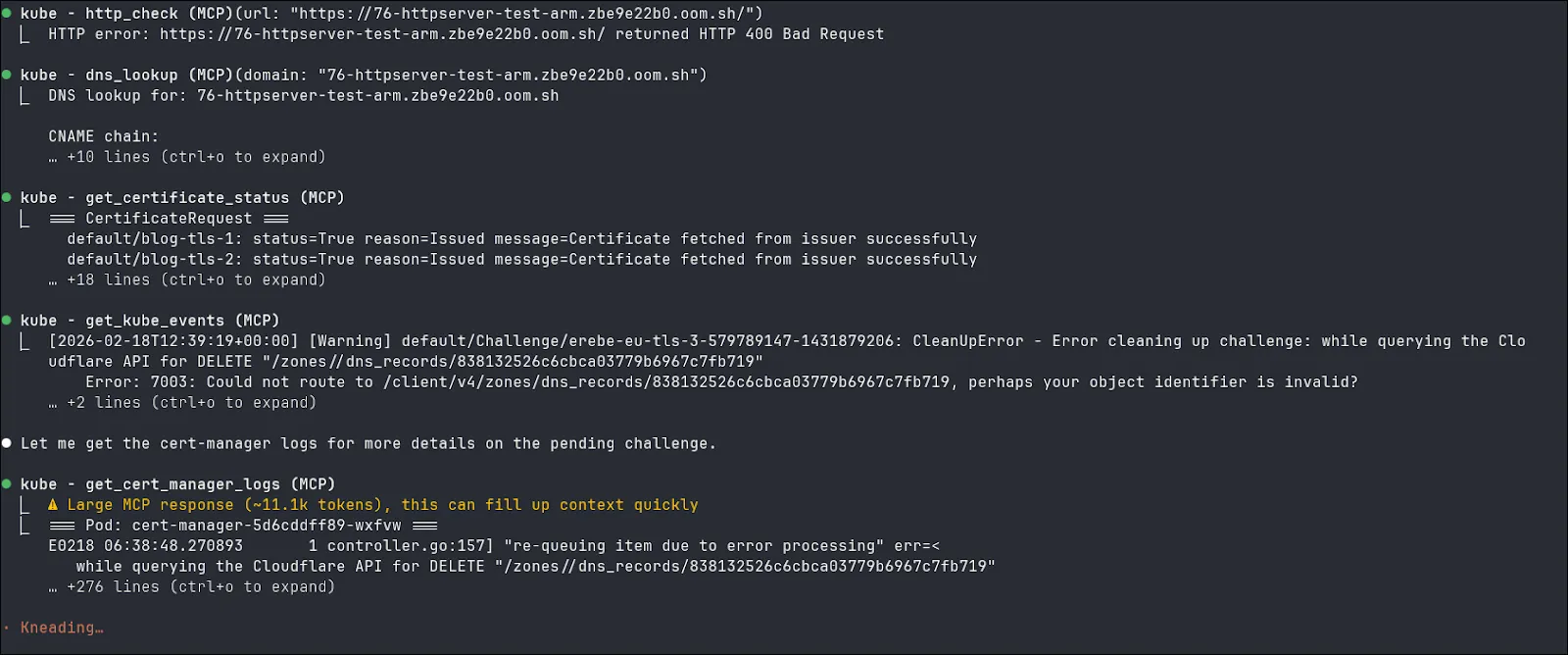
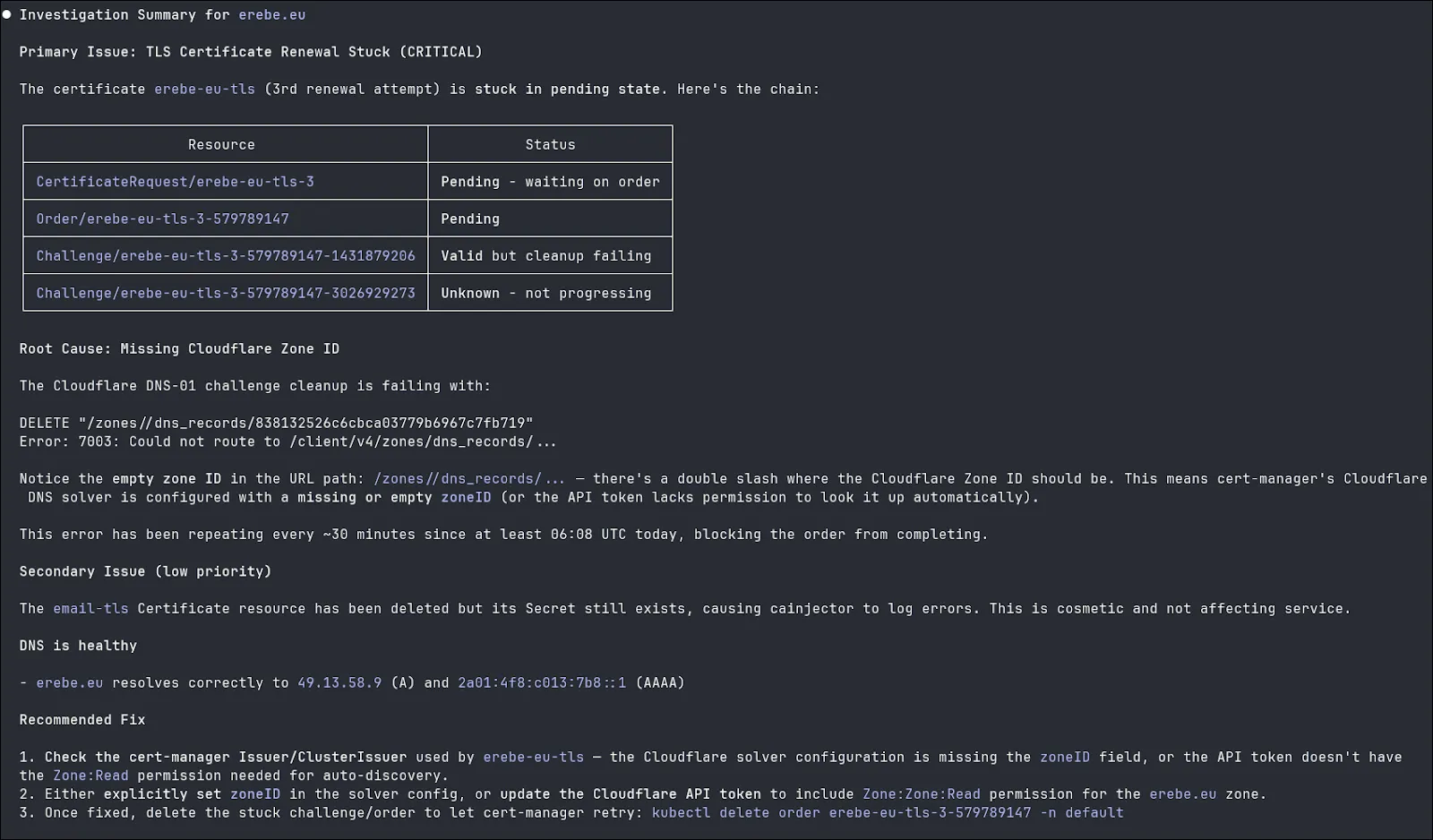
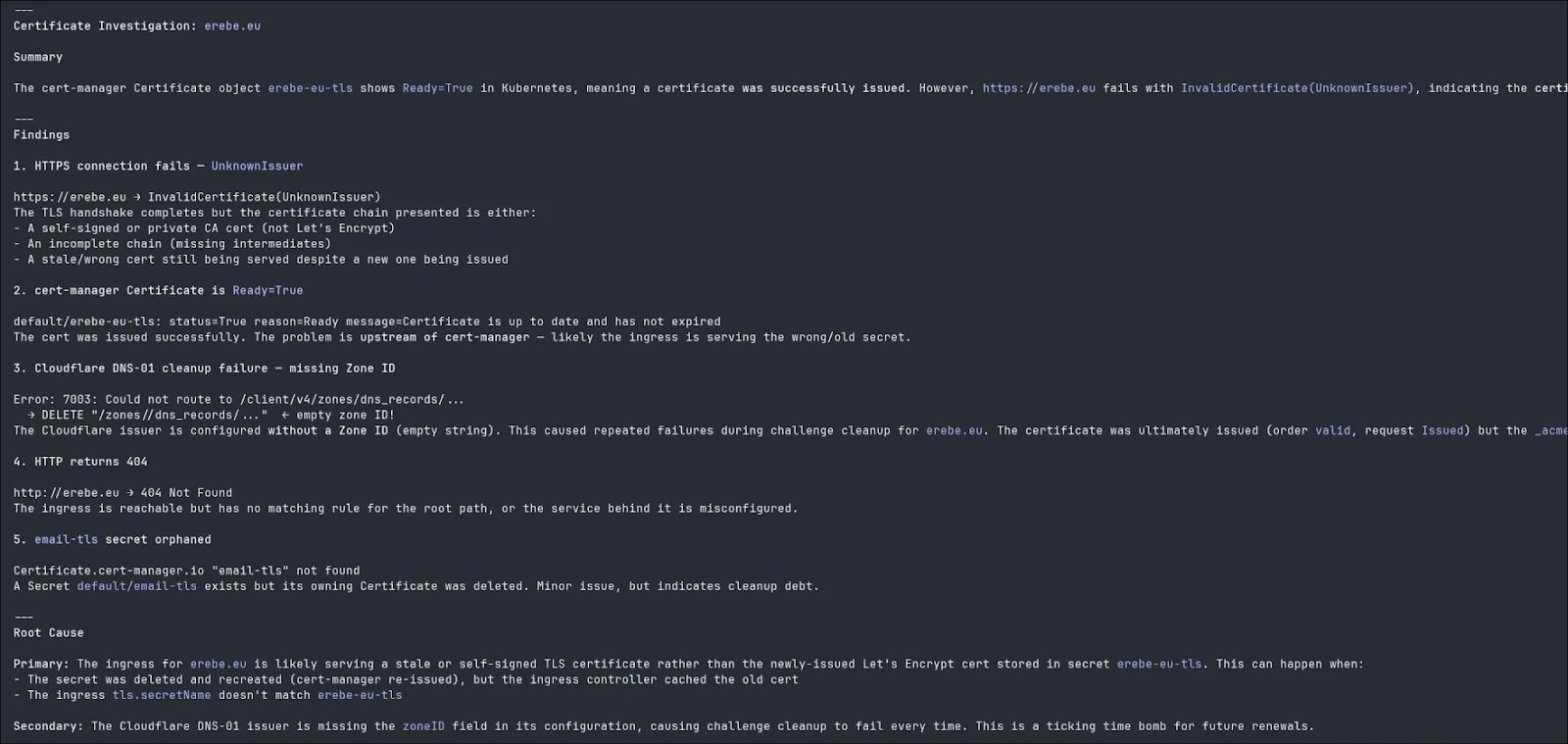
Here you can see that with the help of the MCP server, the LLM have been able to retrieve all the status and log of Kubernetes objects, made DNS queries to verify the CNAME chain and done an http call to verify that the server correctly responded.
Another example where the secret containing the certificate is invalid. With the help of the HTTP call, the LLM is able to tell the certificate is invalid even while all cert-manager objects are green.
The Strategic Shift for Tech Leaders
For an Enterprise, MCP servers represent the Future of Day 2 Operations.
- Executable Knowledge: Your tool is your documentation. There is a single source of truth for "how we investigate."
- Cognitive Offloading: Let the LLM juggle the kubectl commands and log parsing. The human stays in the driver’s seat for the Analysis.
- Onboarding at Scale: New engineers can resolve complex incidents by following a "Guided Investigation" powered by the collective intelligence of your best leads.
At Qovery, we believe your platform should do more than just run code - it should help you understand it. By using MCP as a gateway to your infrastructure, we are moving from "Static Docs" to "Intelligent Operations."
This is why our new MCP server is going to give you access out of the box to all the investigation tools your team needs…Start your free trial today or let’s talk!

.svg)
.svg)
.svg)

Suggested articles


Agentic Kubernetes resource reclamation is the practice of using an autonomous control plane to continuously identify, suspend, and delete idle infrastructure across a multi-cloud Kubernetes fleet. It replaces manual cleanup and reactive autoscaling with intent-based policies that act on business state, eliminating the configuration drift and cloud waste typical of unmanaged fleets.


Kubernetes is an open-source platform that automates the deployment, scaling, and management of containerized applications. While originally designed to orchestrate single-cluster workloads, modern enterprise use cases require managing Kubernetes at fleet scale, coordinating thousands of clusters across multi-cloud environments to enforce cost governance, security policies, and automated lifecycle management.


The shift from AI copilots to autonomous agents is redefining infrastructure requirements. Discover how to build secure, stateful, and compliant Agentic AI systems using Kubernetes, sandboxing, and observability while meeting EU AI Act standards

Effective Kubernetes management in 2026 demands a shift from manual cluster building to intent-based fleet orchestration. By implementing agentic automation on standard EKS, GKE, or AKS clusters, enterprises eliminate operational weight, prevent configuration drift, and proactively control cloud spend without vendor lock-in, enabling effective scaling across massive fleets.

A Kubernetes single pane of glass is a centralized management layer that unifies visibility, access control, cost allocation, and policy enforcement across § cluster in an enterprise fleet for all cloud providers. It replaces the fragmented practice of switching between AWS, GCP, and Azure consoles to govern infrastructure, giving platform teams a single source of truth for multi-cloud Kubernetes operations.

Deploying a Docker container on Kubernetes requires building an image, authenticating with a registry, writing YAML deployment manifests, configuring services, and executing kubectl commands. While necessary to understand, executing this manual workflow across thousands of clusters causes severe configuration drift. Enterprise platform teams use agentic platforms to automate the entire deployment lifecycle.

At enterprise scale, managing provider-specific Kubernetes YAML across multiple clouds creates crippling configuration drift and operational toil. By adopting an agentic Kubernetes management platform, infrastructure teams abstract cloud-specific configurations (like ingress controllers and storage classes) into a single, declarative intent that automatically reconciles across 1,000+ clusters.

To stop GPU costs from destroying SaaS margins, teams must transition from static to consumption-based infrastructure by utilizing Karpenter for dynamic provisioning, maximizing hardware density with NVIDIA MIG, and leveraging Qovery to tie scaling directly to business metrics.


.webp)