
Stop Guessing, Start Shipping. AI-Powered Deployment Troubleshooting


The Problem: Deployment Failures Kill Developer Velocity
AI is accelerating how fast developers write code. More code means more pull requests, more builds, more deployments. And more deployments means more failures. The problem isn't going away. It's getting worse.
A deployment fails. Now what?
Today, a developer facing a failed deployment has three options, all bad. They can try to debug it themselves, which requires expertise in Docker, Kubernetes, cluster configuration, and application settings that most developers don't have. They can guess, changing random settings and retriggering deployments hoping something sticks, burning 30 minutes, an hour, sometimes more. Or they can open a ticket, ping a DevOps engineer on Slack, and wait. Meanwhile, the feature doesn't ship.
Every failed deployment becomes a bottleneck. And the bottleneck always lands on the same few people. Now multiply that by the volume of code AI is helping your team produce.
The Solution: Deployment Copilot
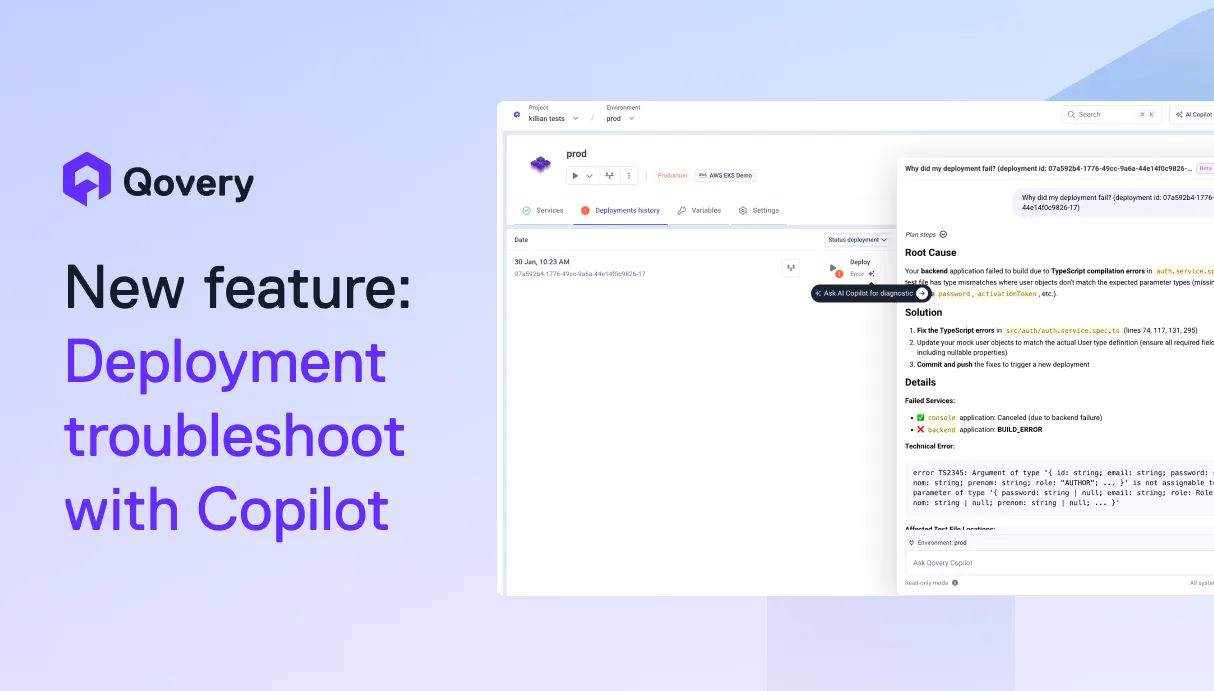
The Qovery AI Copilot analyzes your failed deployment, identifies the root cause, and proposes a concrete fix in seconds, not hours.
Invoke it directly from the deployment logs or deployment history view. The Copilot pulls together everything it needs automatically: application configuration and recent changes, deployment history and timing, application logs and metrics, Kubernetes events and node status. It correlates signals across all of these layers to tell you exactly what went wrong and how to fix it.
This isn't a generic chatbot you paste logs into. Qovery already sits at the intersection of every signal that matters in a deployment: config, history, logs, Kubernetes state. The Copilot leverages that full context natively. No copy-pasting, no context-switching, no guessing.
What's next: the Copilot will be able to execute the proposed fix on your behalf, with your approval. One click to resolve, not just diagnose.
Outcomes for Your Team
- Faster delivery: developers unblock themselves in minutes instead of hours.
- Less friction: no more Slack threads, tickets, or waiting on someone with cluster access.
- Less waiting on DevOps: DevOps engineers stop being the first responder for every deployment issue.
- Scale your engineering team without scaling your DevOps team: onboard more developers without increasing the operational support burden.
Real-World Scenario
A team shares a staging environment across multiple developers. Everything runs fine.. until one day, backend deployments start failing continuously. Builds succeed, but the application crashes shortly after startup.
Without the Copilot, this turns into a multi-hour investigation: checking logs, reviewing recent commits, comparing configurations. With the Copilot, the developers invoke it directly from the deployment view. In seconds, it identifies that a recent commit significantly increased memory consumption at runtime, causing the container to get OOM-killed on startup. The Copilot points to exactly when the failures started, which commit introduced the change, and proposes two paths: verify whether the increased memory usage is expected, or increase the memory allocation.
Issue resolved. No DevOps ticket opened.
How to Use
- A deployment fails. Click the Copilot icon from the deployment logs or deployment history view.
- The Copilot analyzes deployment logs, application logs, Kubernetes events, and configuration changes, then surfaces the root cause and a recommended fix.
- Apply the fix and retrigger your deployment.
Get Started
The AI Copilot is in beta and accessible to everyone! Enable it in your organization settings and try it on your next failed deployment.

.svg)
.svg)
.svg)

Suggested articles


Agentic Kubernetes resource reclamation is the practice of using an autonomous control plane to continuously identify, suspend, and delete idle infrastructure across a multi-cloud Kubernetes fleet. It replaces manual cleanup and reactive autoscaling with intent-based policies that act on business state, eliminating the configuration drift and cloud waste typical of unmanaged fleets.


Kubernetes is an open-source platform that automates the deployment, scaling, and management of containerized applications. While originally designed to orchestrate single-cluster workloads, modern enterprise use cases require managing Kubernetes at fleet scale, coordinating thousands of clusters across multi-cloud environments to enforce cost governance, security policies, and automated lifecycle management.


The shift from AI copilots to autonomous agents is redefining infrastructure requirements. Discover how to build secure, stateful, and compliant Agentic AI systems using Kubernetes, sandboxing, and observability while meeting EU AI Act standards

Effective Kubernetes management in 2026 demands a shift from manual cluster building to intent-based fleet orchestration. By implementing agentic automation on standard EKS, GKE, or AKS clusters, enterprises eliminate operational weight, prevent configuration drift, and proactively control cloud spend without vendor lock-in, enabling effective scaling across massive fleets.

A Kubernetes single pane of glass is a centralized management layer that unifies visibility, access control, cost allocation, and policy enforcement across § cluster in an enterprise fleet for all cloud providers. It replaces the fragmented practice of switching between AWS, GCP, and Azure consoles to govern infrastructure, giving platform teams a single source of truth for multi-cloud Kubernetes operations.

Deploying a Docker container on Kubernetes requires building an image, authenticating with a registry, writing YAML deployment manifests, configuring services, and executing kubectl commands. While necessary to understand, executing this manual workflow across thousands of clusters causes severe configuration drift. Enterprise platform teams use agentic platforms to automate the entire deployment lifecycle.

At enterprise scale, managing provider-specific Kubernetes YAML across multiple clouds creates crippling configuration drift and operational toil. By adopting an agentic Kubernetes management platform, infrastructure teams abstract cloud-specific configurations (like ingress controllers and storage classes) into a single, declarative intent that automatically reconciles across 1,000+ clusters.

To stop GPU costs from destroying SaaS margins, teams must transition from static to consumption-based infrastructure by utilizing Karpenter for dynamic provisioning, maximizing hardware density with NVIDIA MIG, and leveraging Qovery to tie scaling directly to business metrics.


.webp)