







































Top 10 Fargate Alternatives: Simplify Your Container Deployment
Tired of complex cloud setups? Explore the top 10 Fargate alternatives and discover how Qovery can simplify yo...
Read
Qovery is a DevOps Automation Tool that eliminates your DevOps hiring needs. Provision and maintain a secure and compliant infrastructure in hours - not months!





















“Qovery has allowed us to automate our infrastructure provisioning, resulting in higher engineering efficiency while keeping our infrastructure secure.”
 Anthony Mayer, VP Engineering at GetSafe
Anthony Mayer, VP Engineering at GetSafe
Eliminate manual DevOps work and empower developers with our DevOps Automation Tool


The most complete platform for unlocking developer self-service and team velocity.

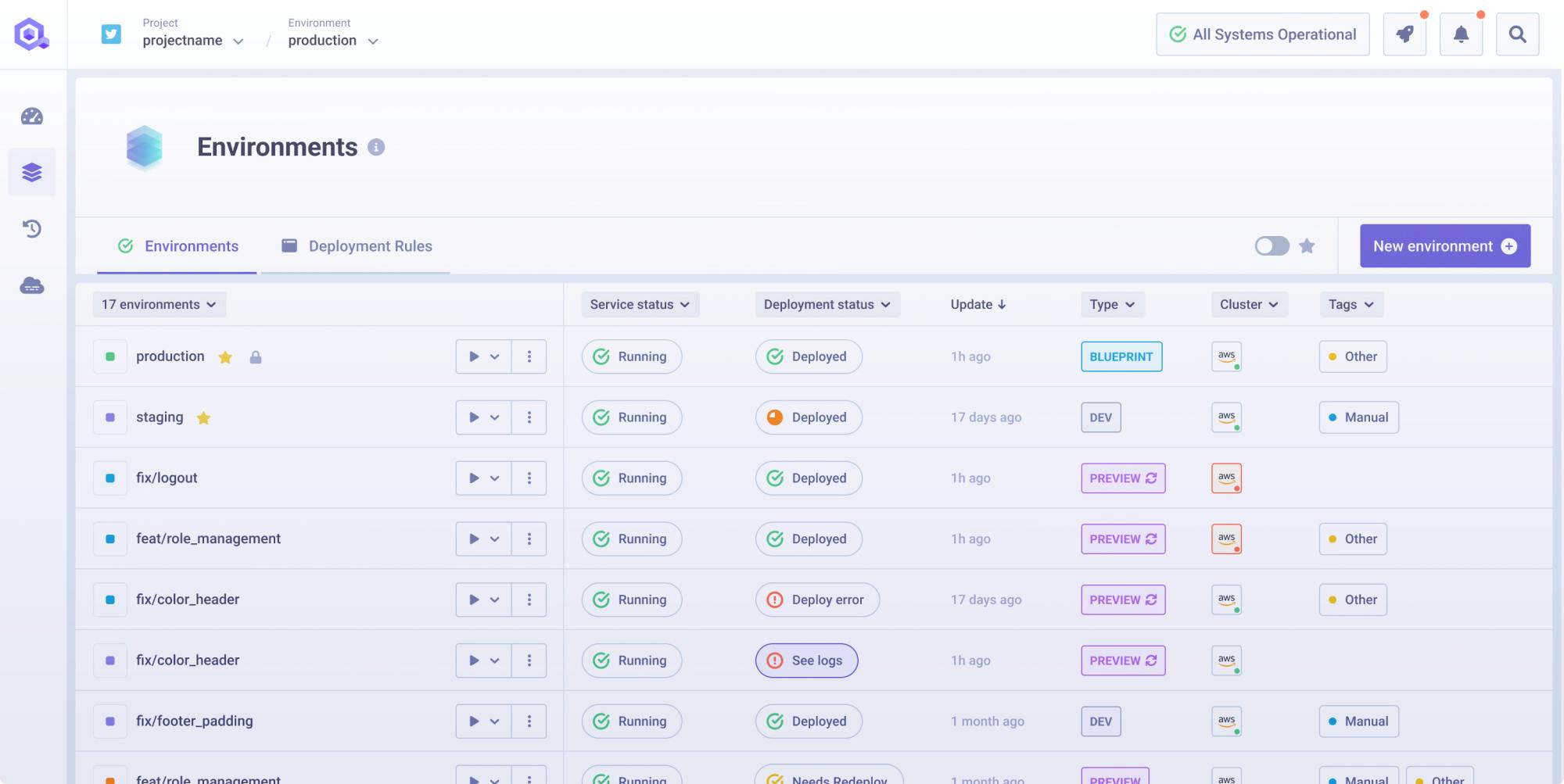
 Environment provisioning
Environment provisioning
 Self-service & Integrations
Self-service & Integrations
 Governance & Custom policies
Governance & Custom policies
 Security & Control
Security & Control
 Cost Optimization
Cost OptimizationAutomate provisioning of infrastructure assets into ready-to-run environments. Eliminate the redundant manual work required to fulfill simple requests for environments, whether for application development, QA & testing, or IT operations.
Learn moreEmpower DevOps teams with self-service control over their infrastructure. Easily integrate with existing tools and workflow for a seamless experience.
Learn moreSet custom policies and governance controls to ensure compliance and maintain control over your infrastructure. Qovery's platform makes it easy to enforce best practices and regulations.
Learn more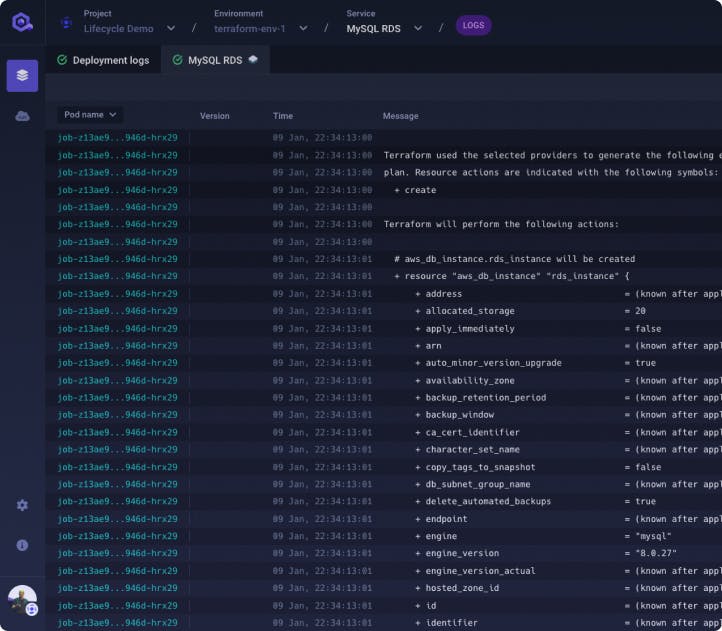
Ensure the security and control of your infrastructure with features such as multi-factor authentication, fine-grained access controls, and secure communication between components. Qovery prioritizes the protection of your assets.
Learn moreQovery helps DevOps teams optimize their cloud costs through various optimization measures, such as sharing the same load balancer between services within the same environment and automatically shutting down environments when not in use. Our platform also offers partnerships and integrations with major cloud providers, including Usage AI, which has been shown to reduce costs by up to 57%. Gain visibility into resource usage and take advantage of cost-saving recommendations to lower your cloud costs even further with Qovery.
Learn more

 CLI
CLI
 API
API
 Terraform Provider
Terraform Provider
 Client (TS, JS, GO..)
Client (TS, JS, GO..)
 Web UI
Web UI
Qovery's DevOps Automation Tool seamlessly integrates with your existing tools and cloud accounts, allowing you to continue using your preferred monitoring, CI/CD, and security solutions. This means you can easily incorporate Qovery into your existing workflow without additional setup or integration efforts.
A few days ago, I chatted with Florian Suchan (CTO and Co-Founder at Papershift) about their journey to easy infrastructure autoscaling. As you will see in the article, they tried a wide range of solutions before finding the right fit; if you feel you’re going through the same journey, this article is for you!
Read this use caseOur users have spoken. Qovery ranks as a G2 high performer across Infrastructure and DevOps categories.
Hello Team, Check out this week’s changelog for exciting updates and enhancements from our team! 🚀 📍Qovery ...
Hello Team, Check out this week’s changelog for exciting updates and enhancements from our team! 🚀 📊 Observa...
Hello Team, Check out this week’s changelog for exciting updates and enhancements from our team! 🚀 Welcome,...
Hello Team, Check out this week’s changelog for exciting updates and enhancements from our team! 🚀 Azure AK...
Hello Team, Check out this week’s changelog for exciting updates and enhancements from our team! 🚀 Road to ...
Hello Team, Check out this week’s changelog for exciting updates and enhancements from our team! 🚀 Cluster ...






.jpg?ixlib=gatsbyFP&auto=compress%2Cformat&fit=max)