
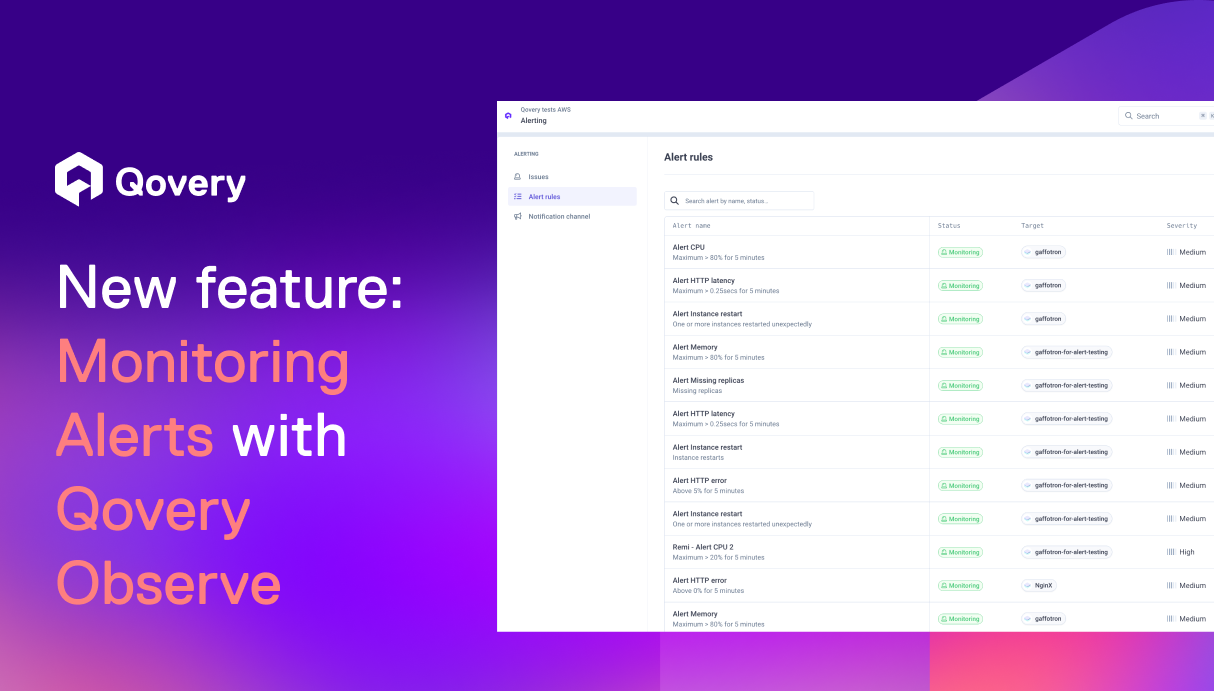
Alerting with guided troubleshooting in Qovery Observe


Incidents are discovered too late and without context
Developers often discover production issues too late, usually through customer complaints or support tickets. By the time they investigate, the incident has already impacted users and valuable context is lost, making troubleshooting slower and more stressful.
This is why we are releasing alerting today, natively integrated into Qovery to help developers detect issues early and move directly toward resolution with full context.
Alerting connected to your deployments and infrastructure, not detached from them
Alerting belongs inside Qovery because the platform already knows how your application is deployed, how it behaves, and what recently changed. Alerts are directly connected to the service, its deployment, and its runtime signals, guiding developers from notification to root cause without leaving the platform.

Outcome for your Teams
- Faster incident detection and diagnosis
- Reduced incident impact
- More reliable services over time
A Real Life Example: From Customer Complaints to Proactive Incident Response
A team was running a customer-facing service that occasionally restarted under high traffic. Before alerting, they only learned about the issue through support tickets, nearly two hours after the first failures.
With Qovery Observe alerting enabled on memory usage and restarts, the team now receives an immediate Slack notification. From the alert, they jump directly into the service monitoring dashboard, where metrics, recent deployment history, and runtime signals are shown together. This makes it immediately clear that a recent deployment increased memory usage under load, leading to OOM restarts. The team can roll back or adjust resources before customers are significantly impacted.
Get Alert Notifications in 3 Simple Steps
1. Define an alert on a service metric or event
2. Receive a notification in the Qovery console or a dedicated Slack channel
3. Open the alert and follow the monitoring dashboards that guide you to the root cause
Want to see it in action? Check the demo below:
Try it now - Detect issues early and fix them with full context
Enable alerting on your critical services today and get guided directly from alert to root cause inside Qovery Observe.
- For all our customers: Get in touch with your CSM to enable the feature
- Not a customer yet? book a demo here!

.svg)
.svg)
.svg)

Suggested articles


At enterprise scale, managing provider-specific Kubernetes YAML across multiple clouds creates crippling configuration drift and operational toil. By adopting an agentic Kubernetes management platform, infrastructure teams abstract cloud-specific configurations (like ingress controllers and storage classes) into a single, declarative intent that automatically reconciles across 1,000+ clusters.


To stop GPU costs from destroying SaaS margins, teams must transition from static to consumption-based infrastructure by utilizing Karpenter for dynamic provisioning, maximizing hardware density with NVIDIA MIG, and leveraging Qovery to tie scaling directly to business metrics.
AI is helping developers write more code, faster than ever. But writing code is only half the story. What happens after? Building, deploying, debugging, scaling. That's where teams still lose hours.We're building Qovery for this era. Not just to deploy your code, but to make everything that comes after writing it just as fast.



By adopting GitOps and utilizing management platforms like Qovery, fintech teams can automatically generate DORA-compliant audit trails, transforming regulatory compliance from a manual, time-consuming chore into an automated, native byproduct of their infrastructure.

Kubernetes success is determined by Day 2 execution, not Day 1 deployment. While migration is a bounded project, maintenance is an infinite loop that often consumes 40% of senior engineering capacity. To protect margins and velocity, enterprises must transition from manual toil to agentic automation that handles scaling, security, and cost.


Day-0 is planning, Day-1 is deployment, and Day-2 is the infinite lifecycle of maintenance. While Day-0/1 are foundational, Day-2 is where enterprise operational debt accumulates. At fleet scale (1,000+ clusters), managing these differences manually is impossible, requiring agentic automation to maintain stability and eliminate toil.



.webp)