
Beyond Compute Constraints: Why AI Success is an Orchestration Problem



The global race for AI has been a hardware sprint. For the past two years, leaders in AI-driven enterprises and cloud-native organizations have focused on one thing: securing GPUs. But as we move into 2026, the challenge has shifted. It’s no longer about how much horsepower you own; it’s about how much of that power actually reaches the model.
We are now facing a massive utilization gap - 35% of enterprises rank increasing GPU utilization as a top priority, yet 44% admit to manually assigning workloads or having no strategy for GPU utilization. While the market remains fixated on compute constraints, the silent killer of AI ROI is idle hardware. In the AI era, underutilized GPUs are a direct leak in the corporate balance sheet.
Efficiency as Operational Autonomy
In Europe, where energy costs, cloud sovereignty initiatives, and industrial competitiveness dominate the agenda, efficiency has become a strategic weapon. The ability to run AI workloads on your own terms is what gives operational autonomy, without paying an “inefficiency tax” on every inference and training cycle.
Recent data shows that in complex multimodal AI environments, up to 84% of GPU capacity is wasted due to CPU bottlenecks and inefficient scheduling. For German enterprises, that translates into millions of euros in “ghost” expenses every year. (Source: NeuReality 2025).
AI Is an Orchestration Problem, Not a Compute Problem
Many still frame AI as a data problem or a hardware problem. In reality, it is an orchestration problem; just as in the 1990s and 2000s, when the memory wall forced computer architects to rethink efficiency rather than just add more hardware.
Kubernetes has emerged as the operating system of the AI era, moving beyond simple container deployment to unify fragmented infrastructure resources, including GPUs, into a single platform.
Within this context, it enables fractional GPU usage, which allows multiple workloads to share high-end GPUs instead of leaving them idle. It also provides dynamic scheduling to ensure compute resources are available precisely when models need them. Finally, it facilitates infrastructure portability, reducing dependency on a single cloud or hosting provider and unlocking price arbitrage across various platforms.
But orchestration alone is no longer enough.
The Missing Layer: AI Copilots for Infrastructure
The real cost of AI isn’t deployment - it’s Day 2 operations: monitoring, troubleshooting, scaling, and optimization under live workloads. This is where organizations lose both money and velocity.
This is why we are seeing the rise of AI copilots for infrastructure, autonomous systems that sit above Kubernetes and continuously optimize how resources are used. Instead of engineers manually tuning clusters, these copilots provide self-healing by detecting and remediating deployment failures in real time, always under your control to prevent costly downtime.
Furthermore, they enable autonomous optimization by continuously analyzing utilization to consolidate workloads, effectively shrinking the cloud bill without human intervention. This shift democratizes control by allowing teams to manage complex infrastructure through natural language, bypassing the "Kubernetes skill gap" entirely.
Intelligence Over Hardware
By shifting from manual infrastructure management to AI-driven orchestration, enterprises can dramatically improve infrastructure efficiency, allowing engineering teams to spend less time on maintenance and more on delivering AI value/business value
I believe that the winners of the AI era won’t be the companies with the most GPUs, they’ll be the ones that manage their compute with the highest level of operational intelligence.
Today and tomorrow, infrastructure is a competitive frontline.

.svg)
.svg)
.svg)

Suggested articles


At enterprise scale, managing provider-specific Kubernetes YAML across multiple clouds creates crippling configuration drift and operational toil. By adopting an agentic Kubernetes management platform, infrastructure teams abstract cloud-specific configurations (like ingress controllers and storage classes) into a single, declarative intent that automatically reconciles across 1,000+ clusters.


To stop GPU costs from destroying SaaS margins, teams must transition from static to consumption-based infrastructure by utilizing Karpenter for dynamic provisioning, maximizing hardware density with NVIDIA MIG, and leveraging Qovery to tie scaling directly to business metrics.
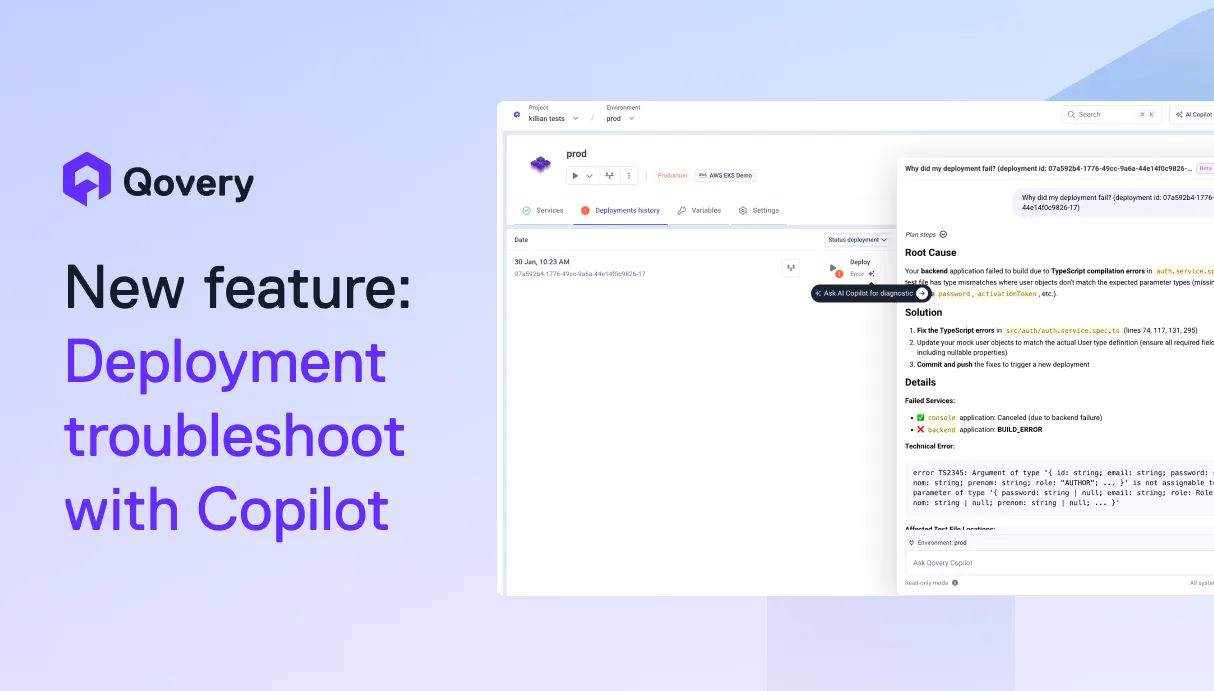
AI is helping developers write more code, faster than ever. But writing code is only half the story. What happens after? Building, deploying, debugging, scaling. That's where teams still lose hours.We're building Qovery for this era. Not just to deploy your code, but to make everything that comes after writing it just as fast.




By adopting GitOps and utilizing management platforms like Qovery, fintech teams can automatically generate DORA-compliant audit trails, transforming regulatory compliance from a manual, time-consuming chore into an automated, native byproduct of their infrastructure.

Kubernetes success is determined by Day 2 execution, not Day 1 deployment. While migration is a bounded project, maintenance is an infinite loop that often consumes 40% of senior engineering capacity. To protect margins and velocity, enterprises must transition from manual toil to agentic automation that handles scaling, security, and cost.


Day-0 is planning, Day-1 is deployment, and Day-2 is the infinite lifecycle of maintenance. While Day-0/1 are foundational, Day-2 is where enterprise operational debt accumulates. At fleet scale (1,000+ clusters), managing these differences manually is impossible, requiring agentic automation to maintain stability and eliminate toil.



.webp)