
Kubernetes multi-cluster architecture: solving day-2 fleet sprawl



Key points:
- Acknowledge the sprawl: Clusters multiply rapidly due to compliance and latency requirements, turning into isolated islands that multiply Day-2 maintenance.
- Evaluate architectures: CI/CD scripting and directory-based GitOps create severe context-switching taxes at scale, while KubeFed (federation) fails due to single-point-of-failure bottlenecks.
- Implement centralized control: The enterprise standard is "centralized management, decentralized execution", maintaining cluster independence while standardizing deployments through a unified control plane.
Most organizations do not plan for multi-cluster Kubernetes, they drift into it.
It starts with a single EKS or GKE deployment. Then comes a second cluster for GDPR compliance, another for a low-latency edge case, and suddenly, you are managing an operational surface area that grows faster than your engineering team can scale.
Kubernetes was designed to orchestrate containers, not to coordinate state across a global fleet. Without a dedicated management layer, you are not running a distributed system; you are running isolated islands, each with its own configuration drift, security gaps, and severe context-switching tax.
Here is an architectural evaluation of how to stop managing clusters individually and start orchestrating them as a unified fleet.
The 1,000-cluster reality: surviving the day-2 complexity tax
Before exploring specific architectures, platform architects must recognize the FinOps and resourcing impact of fleet sprawl. Managing a handful of clusters is a standard operational task. Scaling to dozens or hundreds of clusters creates an exponential Day-2 maintenance burden. Troubleshooting, upgrading, and auditing configuration drift across disparate clusters consumes the vast majority of DevOps resources, reducing platform engineering to reactive toil. To survive at an enterprise scale, teams must transition from treating clusters as bespoke pets to treating them as programmable, agentic compute pools via a unified control plane.
🚀 Real-world proof
Bhuma transitioned to EKS to handle growing containerization needs, but their DevOps team immediately faced severe bottlenecks attempting to manually automate testing and integration across environments.
⭐ The result: By utilizing Qovery as a centralized control plane, Bhuma automated their integration pipelines and eliminated manual infrastructure testing toil entirely. Read the Bhuma case study.
Approaches to multi-cluster management
Organizations typically arrive at multi-cluster management through one of three paths, each with distinct trade-offs in maintenance burden and reliability.
The scripting approach
The most common starting point to implementing multi-cluster management is extending existing CI/CD pipelines. Teams add kubectl context switches and conditional logic to their deployment scripts, targeting different clusters based on environment variables or branch names. A typical GitHub Actions workflow might now include a strategy for deploying to three clusters, each requiring its own kubeconfig, set of secrets, and post-deployment verification steps.
Using this approach, the maintenance cost scales proportionally with the number of clusters and services:
- Proportional Updates: Every new cluster requires updating every pipeline that deploys to it.
- Accumulating Logic: Conditional logic accumulates, and a single missed condition in a pipeline can produce a partial rollout that takes hours to diagnose.
- Bespoke Platforms: Teams that start here usually end up maintaining a bespoke deployment platform built from shell scripts and YAML templating.
The GitOps approach
ArgoCD and Flux represent a significant improvement over the previous model. Both tools formalize the relationship between a Git repository and a cluster's desired state, continuously reconciling live configuration against declared manifests. For multi-cluster management, resources for each target cluster can get generated from a single template.
This approach still brings a non-trivial operational overhead. Multi-cluster ArgoCD requires careful design, configuration, and setup:
- Configuration Duplication: Directory-per-cluster, which duplicates manifests across directories, is a standard pattern making global changes harder as it needs to be propagated across many configurations.
- Implementation Time: Setting up ArgoCD to manage ten clusters across multiple cloud providers with appropriate RBAC and configurations is a project measured in weeks for an experienced team.
- Operational Gaps: This setup also doesn’t cater for cluster lifecycle, cross-cluster observability, or environment promotion.

The federation approach
Kubernetes Federation (KubeFed) is an attempt to solve multi-cluster resource distribution. It introduced a control plane that could propagate Kubernetes resources, deployments, services, and ConfigMaps across member clusters using a template model. In theory, you declared your workload once, and KubeFed distributed it to the clusters you specified.
In practice, the project stalled. KubeFed v1 was deprecated due to fundamental architectural issues:
- Architectural Bottlenecks: The control plane was a single point of failure and operated on a lowest-common-denominator API.
- Implementation Complexity: This made for a too complex effort and implementation, which eventually slowed the federation model down to deprecation.
The federation model failed because it tried to make multiple clusters behave like one logical cluster. What organizations need is a management layer that treats clusters as independent execution targets while providing unified visibility and consistent deployment across all of them.
The operational reality
Before diving into the technical mechanics of multi-cluster scale, it’s important to evaluate if your organization is ready for this architectural shift. See our breakdown of 'Kubernetes Multi-Cluster: Why and When To Use Them' for the strategic pros and cons.
The daily experience of managing multiple clusters is defined by context switching. Checking the health of a service running in three regions means running kubectl get pods in different contexts, fetching logs, and metrics often following the same pattern.
Without a centralized view, this fragmentation compounds rapidly:
- Incident Friction: An investigation can typically be replicated across multiple clusters to perform proper research, cross-referencing, and identifying root causes.
- Visibility Blindspots: Teams cannot easily identify issues spanning multiple environments or detect configuration drifts between clusters. These factors require manual auditing or custom tooling to detect.
- Promotion Risks: Promoting applications between environments also is subject to complications with multiple clusters. It usually involves manually replicating configuration across cluster boundaries, with each replication being another opportunity for drift to enter the system.
Centralized management, decentralized execution
The pattern that works is one where clusters remain architecturally independent but operationally unified. Each cluster runs its control plane, networking stack, and workloads, with a management layer running above the clusters, providing a single interface for deploying applications, enforcing standards, and observing state across the entire fleet.
This is the model Qovery implements. The platform connects to managed Kubernetes clusters, whether EKS, GKE, AKS, or others, and registers them within a single organization. Clusters retain their independence by running in the organization's cloud accounts with safe networking and security boundaries. Qovery does not merge them or abstract them into a single logical cluster, but as separate execution targets with a unified management interface.
Cluster-agnostic deployment
Within a Qovery organization, teams can connect clusters from different cloud providers and regions to the same account. An EKS cluster in us-east-1, a GKE cluster in europe-west1, and an AKS cluster in southeastasia can all appear in the same console. Deploying an application to any of these clusters uses the same workflow, as the service definition, its Git source, build configuration, and environment variables are portable across clusters.
This eliminates the per-cluster pipeline logic that makes the scripting approach unsustainable. Instead of maintaining separate deployment configurations for each cluster, teams define the application once and target it to whatever cluster the deployment requires.
Environment management across clusters
Qovery's environment model maps directly to the multi-cluster promotion problem. An environment, a group of services with their databases, configurations, and secrets, can be deployed to one cluster and then promoted to another. Development runs on a dedicated cluster, is then promoted to a staging one when ready, and is finally deployed to multiple production clusters for regional redundancy.
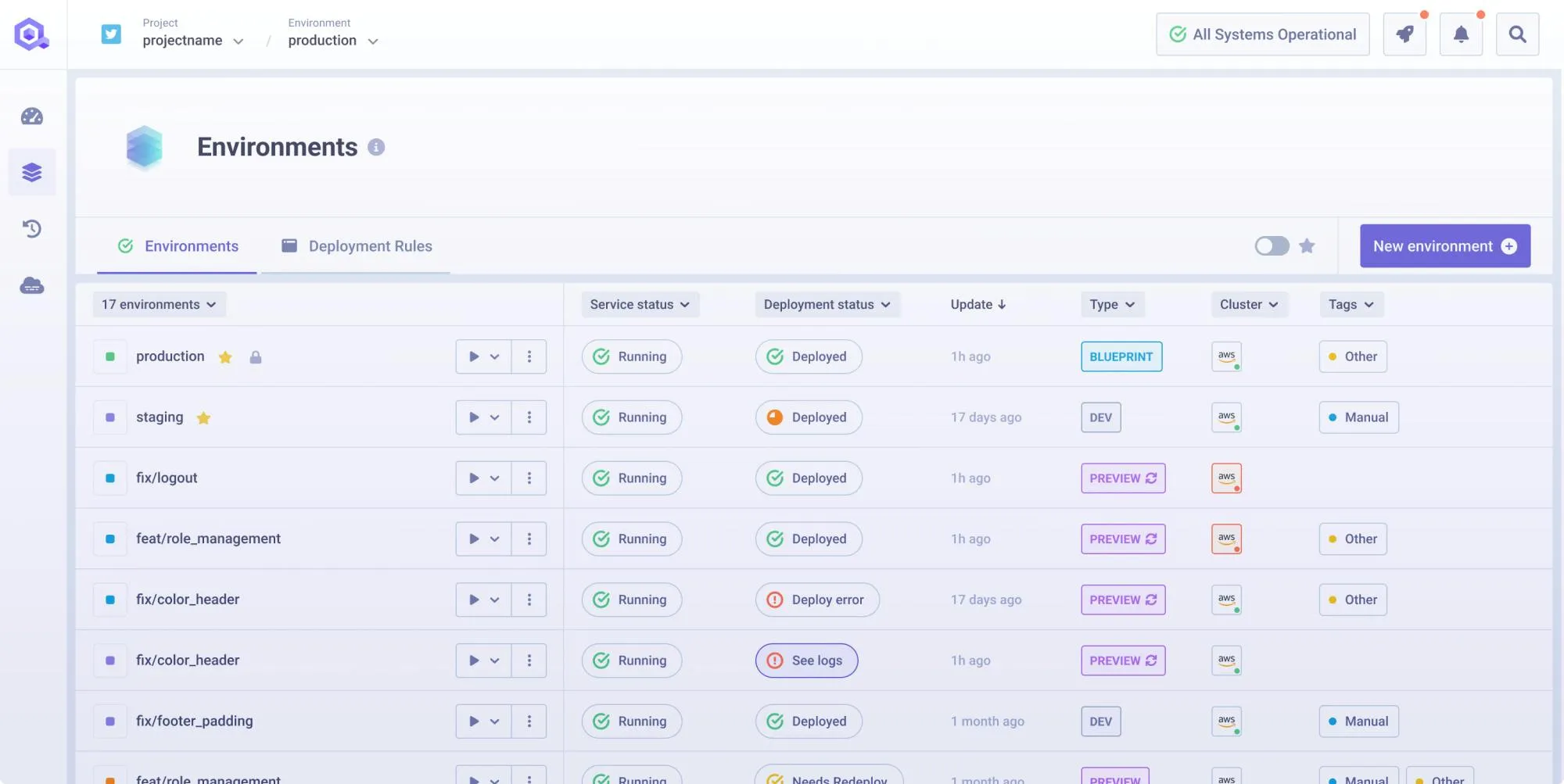
This platform-level promotion solves several operational headaches:
- Zero-Drift Promotion: The promotion carries the full environment definition: every service, every variable, every dependency, so that the team does not need to manually recreate the environment on the target cluster. This removes the opportunity for drift to occur during manual promotion, where a variable gets missed or a resource limit gets changed between stages.
- Rapid Regional Expansion: For organizations expanding into new regions, Qovery's clone feature copies an entire environment, its microservices, database configurations, and environment variables, to a different cluster.
- Compliance & DR: Cloning a US production environment to an EU cluster for GDPR compliance takes seconds rather than the days or weeks of manual infrastructure replication. This capability also applies to disaster recovery testing, where teams can clone production to a DR cluster, validate failover behavior, and tear down the clone without affecting the live environment.
Standardization without federation
Where KubeFed tried to standardize by merging clusters into one API surface, Qovery standardizes through consistent deployment rules applied at the organization level. All clusters within the organization follow the same deployment pipelines and access controls. When the platform team updates a deployment standard, it applies across every cluster.
This approach preserves the isolation benefits that motivated multi-cluster architecture in the first place. An incident on the EU production cluster does not propagate to the US cluster because they are separate infrastructure, but their configurations remain consistent because the management layer enforces uniformity.
Unified observability
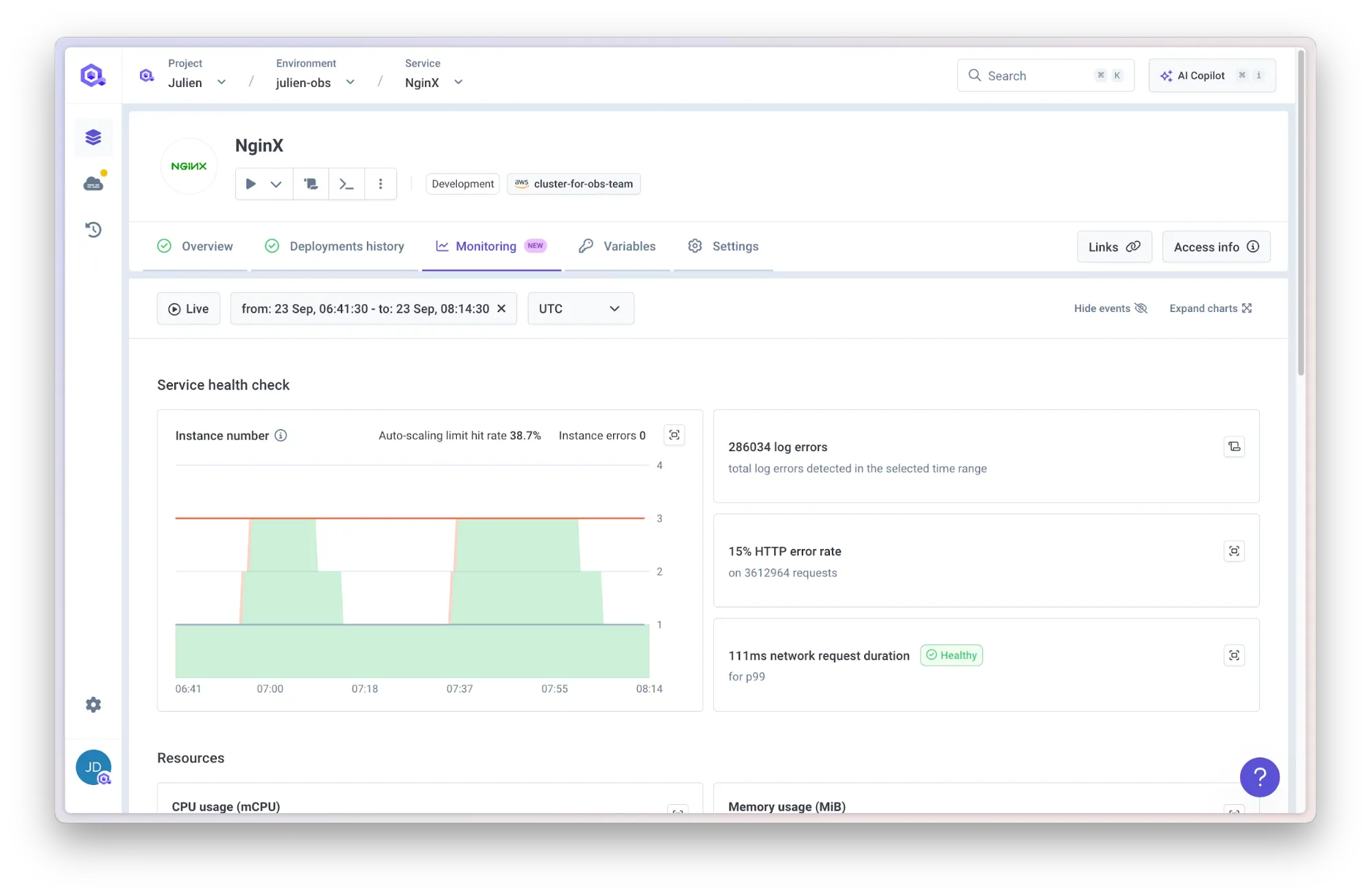
A single dashboard shows every cluster, environment, and service in the organization. Teams can view logs from a production application in Asia and a staging application in the US from the same interface, without switching kubectl contexts or navigating between cloud provider consoles. Resource usage, deployment status, and service health are visible across the fleet from one view.
For teams that have grown accustomed to the context-switching tax of multi-cluster operations, this is where the day-to-day experience changes most, greatly simplifying incident investigation with a fleet-wide view rather than a per-cluster hunt.
Beyond sprawl: the future of global fleet orchestration
Multi-cluster isn't just an architectural choice; it’s a response to reality.
Data residency, blast radius reduction, and latency aren’t going away. But the "management gap" is what kills engineering velocity. Cluster federation failed because it tried to force multiple clusters into one logical box.
The future is keeping your infrastructure independent but your operations unified. When you stop treating every cluster as a bespoke pet and start using a single control plane for environment cloning and cross-cluster promotion, you turn a "management nightmare" into a strategic advantage.
Frequently Asked Questions (FAQs)
Q: What is Kubernetes cluster sprawl?
A: Kubernetes cluster sprawl occurs when an organization rapidly provisions multiple clusters (often for different regions, compliance reasons, or specific teams) without a centralized management strategy. This leads to configuration drift, security blind spots, and a massive maintenance burden for platform engineering teams.
Q: Why did Kubernetes Federation (KubeFed) fail?
A: KubeFed attempted to merge multiple independent clusters into one single logical cluster. This created architectural bottlenecks, a single point of failure in the control plane, and immense configuration complexity. Organizations realized they needed to keep clusters architecturally independent to isolate failures, rather than merging them.
Q: Why is managing multiple clusters with GitOps or CI/CD scripts difficult?
A: Using CI/CD scripts requires writing complex conditional logic for every single cluster, which scales poorly and breaks easily. While GitOps tools like ArgoCD are better, managing a fleet requires duplicating manifests across multiple directories, making global updates incredibly tedious and time-consuming to propagate.
Q: How does Qovery enable multi-cluster management?
A: Qovery uses a "Centralized Management, Decentralized Execution" model. It provides a single unified control plane to manage deployments, observability, and environment cloning across AWS, GCP, and Azure. Crucially, it keeps the underlying clusters architecturally independent, ensuring blast-radius isolation without the "context-switching tax" of manual management.

.svg)
.svg)
.svg)

Suggested articles


At enterprise scale, managing provider-specific Kubernetes YAML across multiple clouds creates crippling configuration drift and operational toil. By adopting an agentic Kubernetes management platform, infrastructure teams abstract cloud-specific configurations (like ingress controllers and storage classes) into a single, declarative intent that automatically reconciles across 1,000+ clusters.

To stop GPU costs from destroying SaaS margins, teams must transition from static to consumption-based infrastructure by utilizing Karpenter for dynamic provisioning, maximizing hardware density with NVIDIA MIG, and leveraging Qovery to tie scaling directly to business metrics.
AI is helping developers write more code, faster than ever. But writing code is only half the story. What happens after? Building, deploying, debugging, scaling. That's where teams still lose hours.We're building Qovery for this era. Not just to deploy your code, but to make everything that comes after writing it just as fast.




By adopting GitOps and utilizing management platforms like Qovery, fintech teams can automatically generate DORA-compliant audit trails, transforming regulatory compliance from a manual, time-consuming chore into an automated, native byproduct of their infrastructure.

Kubernetes success is determined by Day 2 execution, not Day 1 deployment. While migration is a bounded project, maintenance is an infinite loop that often consumes 40% of senior engineering capacity. To protect margins and velocity, enterprises must transition from manual toil to agentic automation that handles scaling, security, and cost.


Day-0 is planning, Day-1 is deployment, and Day-2 is the infinite lifecycle of maintenance. While Day-0/1 are foundational, Day-2 is where enterprise operational debt accumulates. At fleet scale (1,000+ clusters), managing these differences manually is impossible, requiring agentic automation to maintain stability and eliminate toil.



.webp)